[논문리뷰] An Exploratory Study on Long Dialogue Summarization: What Works and What's Next

0. 핵심 내용 3줄 요약
1. 기존 Transformer based Model은 Input sequence의 길이가 제한되어 있어서 Dialogue같은 Long Text를 요약하는데 어려움이 있다.
2. Dialogue(Long Text)를 요약하기 위해서 1) Longformer 2) retrieve-then-summarize pipline 3)hierarchical dialogue encoding models such as HMNet 이 제안 되었다.
3. 위 세 모델에 대하여 QMSum, MediaSum, SummScreen 데이터셋으로 실험을 했을 때 retrieve-then-summarizae pipline이 가장 좋은 성능을 보였다. 이에 더하여 강력한 retrueval model과 추가적인 summerization dataset을 이용하면 더욱 좋은 성능을 낼 수 있음을 밝혔다.
1. Introduction
- 이전에는 20턴 이하의 비교적 짧은 대화 요약에 집중하였다면, 최근 굉장히 긴 대화를 요약하는 것에 집중하고 있다.
- 하지만, 요약에서 좋은 성능을 보이는 Pretrained Transformer 모델들은 Input Sequence의 길이에 제한이 있기 때문에 긴 대화를 요약하는 것이 불가능하다.
- Main Challenge : How can we effectively use the current neural summarization models on dialogues that greatly exceed their length limits?
- 추가적으로 일반적인 Document Summerization과 비교하면, Dialogues는 Context에 의존하며 상호작용을 만들어내는 특성을 가지고 있다. 이 이슈를 해결하기 위해 대화의 Turn-Level의 Hierachocal Methods가 제안되었다.
- 본 논문에서는 세 가지 모델 1) Longformer 2) retrieve-then-summarize pipline 3)hierarchical dialogue encoding models such as HMNet 을 여러 데이터셋( QMSum, MediaSum, SummScreen)에 대하여 실험을 진행한다.
2. Related Work
- Transformer를 기반으로 하는 모델들은 Input 길이의 제곱배에 비례하는 연산량을 요구하기 때문에 input의 길이에 제한이 생긴다.
- 이러한 Issue를 해결하기 위해 Sliding window and Global Attention을 이용한 Longformer, Sliding window and Global Attention을 random하게 combination하여 시간복잡도가 선형에 근사하게 만든 BigBird 등이 제안되었다.
- 기존 Long Text Summerization은 Document Summerization에 집중되어 있어서 Dialoge Summerization은 연구가 활발하게 이뤄지지 못 하였다.
3. Mothodology
3.1 Datasets
- QMSum : Query Based Multi Domain Meeting Summarization Dataset annotated by humans.
- MediaSum : Large scale media interview dataset. It contains short summaries.
- SummScreen : Dialogue Summerization dataset consisting of TV series transcripts and human annotated summaries.

3.2 Models
3.2.1 Retrieve-then-summarize Pipeline
- Long Text에서 relevant subtext를 찾아낸 이후 subtext에 대해서 Summrizaion을 한다.
- Retrivers 방식으로는 TF-IDF, BM25(TF-IDF 변형), Locator(BERT와 CNN을 섞은 Utterance Locator Model)를 이용한다.
- Summerization 모델로는 Pretrained BART-Large을 이용한다.
3.2.2 End-to-End Summarization Models
BART
- Transformer 기반의 encoder-decoder model.
- Text Generation에서 Sota의 성능을 보였다.
- 본 논문에서는 다른 Setting과 ablation study 진행을 위하여 baseLine으로 사용
- 1024개의 Input Sequence 제한이 있다.
HMNet
- Dialogue Summerization을 위한 Hierachical Network
- Token level의 encoder-to-encoder와 Turn Level의 aggregation encoder 사용.
- BART보다 8배 큰 8192개의 Input sequence 제한이 있다.
Longformer
- Sliding window attention + Golbal Attention을 도입하여 Self-Attention을 계산합으로 계산 복잡도를 효과적으로 줄인 Transformer 변형 모델
- 16K개의 Input Sequence까지 처리 할 수 있는 능력을 가지고 있음
- 본 논문의 실험에선 4096개의 Input sequence의 제한을 두어 진행
4. Result and Analysis
4.1 Dealing with Long Dialogues
- 서로 다른 Retreval 방법에 대한 Long input 처리 능력을 평가하기 위해 QMSum데이터로 실험을 진행
- BM25 방식의 Retriveval이 가장 좋은 성능을 보였으며, BART와 Longformer보다 좋은 성능을 보임.
- Gold Span이 주어진 경우 Summarization 성능이 올라감. 즉, Retrival 성능이 좋아질수록 Retrieve-then-Summarizae Pipline의 성능 향상을 기대할 수 있음.

4.2 Robustness to Input Length
- BART와 HMNet에 대하여 다양한 길이의 Input에 얼마나 Robust한 성능을 보이는지 실험 진행
- BART는 길이가 길어질수록 성능 하락(1024Token이 넘어가는 Token는 Cut-off하기 때문에)
- HMNet은 길이가 길어져도 Robust한 성능을 보임

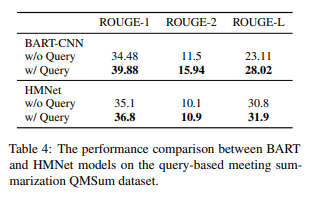
4.3 Incorporation Queries
- 특정 Query에 대한 Dialogue Summarization 성능 비교(QMSum과 같은 데이터)
- Query를 주었을 때와 주지 않았을 때도 함께 성능을 비교
- Query가 주어졌을 때 두 모델 모두 성능이 올라갔으며, HMNet보다 BART가 좋은 성능을 보임
(주의! Table의 BART-CNN은 BART와 Convolutaional Neural Net의 결합이 아닌, CNN-DailyMail 데이터로 사전학습한 BART)
4.4 Transfer Ability between Different Task
- Dialogue Dataset은 보통 크기가 작기 때문에 다른 Dataset으로부터 Transfer Learing의 영향을 많이 받을 것으로 예상
- BART-Large Model을 이용하여 Dateset별 Transfer Ablilty 실험 진행
- 대체로 CNN-DailyMail 데이터가 좋은 성능을 보임

4.5 Case Study
- BART-CNN 모델이 Syntax Error가 적게 발생함
- BART-MediaSum 모델이 Short Inpunt에 대해서는 좋은 성능을 보임
- 핵심 내용이 들어있는 Subtext를 발췌하여 BART-CNN을 사용하는 것을 권장

5. Future Work
- Utterance Retrival 자체도 굉장히 Challenging 한 분야
- Pretrain을 위한 Dataset 구축
- Query와 Text를 어떻게 Nureal Model에서 결합시킬 것인가
- Input Sequence에 Roburst한 모델