
티스토리 뷰
본 포스팅은 『텐서플로2와 머신러닝으로 시작하는 자연어처리』를 참고하여 만들어졌습니다.
https://wikibook.co.kr/nlp-tf2/
자연어 처리를 위해서는 우선 텍스트에 대한 정보를 단위별로 나누는 것이 일반적이다. 예측해야 할 정보(문장 혹은 발화)를 하나의 특정 기본 단위로 자르는 것을 토크나이징이라고 한다. 파이썬을 이용하면 이러한 작업을 라이브러리를 통해 간편하게 처리할 수 있다. 토크나이징을 할 때는 언어의 특징에 따라 처리 방법이 달라지므로 영어 토크나이징과 한글 토크나이징을 구분해서 알아보자.
1. 영어 토크나이징 라이브러리
영어의 경우 NLTK(Natural Language Toolkit)와 Spacy가 토크나이징에 많이 쓰이는 대표적인 라이브러리이다.
1) NLTK (Natural Language Toolkit)
NLTK는 파이썬에서 영어 텍스트 전처리 작업을 하는 데 많이 쓰이는 라이브러리이다. 이 라이브러리는 50여 개가 넘는 말뭉치 리소스를 활용해 영어 텍스트를 분석할 수 있게 제공한다. 직관적으로 함수를 쉽게 사용할 수 있게 구성돼 있어 빠르게 텍스트 전처리를 할 수 있다.
토크나이징
토크나이징이란 텍스트에 대해 특정 기준 단위로 문장을 나누는 것을 의미한다. 예를 들면, 문장을 단어 기준으로 나누거나 전체 글을 문장 단위로 나누는 것들이 토크나이징에 해당한다. 파이썬에서 간단하게 문자열에 대해 split 함수를 사용해서 나눌 수도 있지만 라이브러리를 사용하면 훨씬 더 간편하고 효과적으로 토크나이징 할 수 있다.
이제 라이브러리를 이용해 직접 몇 가지 텍스트 데이터에 대해 토크나이징해보자. 먼저 단어를 기준으로 진행한 후 그 다음으로 문장 단위로 토크다이징 해보자.
단어 단위 토크나이징
텍스트 데이터를 각 단어를 기준으로 토크나이징해보자. 우선 라이브러리의 tokenize 모듈에 word_tokenize를 불러온 후 사용하면 된다.
from nltk.tokenize import word_tokenize
sentence = 'Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. The result is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.'
print(word_tokenize(sentence))['Natural', 'language', 'processing', '(', 'NLP', ')', 'is', 'a', 'subfield', 'of', 'linguistics', ',', 'computer', 'science', ',', 'and', 'artificial', 'intelligence', 'concerned', 'with', 'the', 'interactions', 'between', 'computers', 'and', 'human', 'language', ',', 'in', 'particular', 'how', 'to', 'program', 'computers', 'to', 'process', 'and', 'analyze', 'large', 'amounts', 'of', 'natural', 'language', 'data', '.', 'The', 'result', 'is', 'a', 'computer', 'capable', 'of', '``', 'understanding', "''", 'the', 'contents', 'of', 'documents', ',', 'including', 'the', 'contextual', 'nuances', 'of', 'the', 'language', 'within', 'them', '.', 'The', 'technology', 'can', 'then', 'accurately', 'extract', 'information', 'and', 'insights', 'contained', 'in', 'the', 'documents', 'as', 'well', 'as', 'categorize', 'and', 'organize', 'the', 'documents', 'themselves', '.']
영어 텍스트를 정의한 후 word_tokenize 함수에 적용하면 위와 같이 구분된 리스트를 받을 수 있다. 결과를 보면 모두 단어로 구분돼 있고, 특수 문자의 경우 따로 구분된 것을 볼 수 있다. 이렇게 별다른 설정 없이 함수에 데이터를 적용하기만 해도 간단하게 토크나이징된 결과를 받을 수 있다.
문장 단위 토크나이징
경우에 따라 텍스트 데이터를 우선 단어가 아닌 문장으로 나눠야 하는 경우가 있다. 예를 들어 데이터가 문단으로 구성돼 있어서 문단을 먼저 문장으로 나눈 후 그 결과를 다시 단어로 나눠야 하는 경우가 있다. 이런 경우에 문장 단위의 토크나이징이 필요하다. 역시 NLTK의 라이브러리를 사용하면 쉽게 토크나이징할 수 있다. 앞서 불러왔던 것처럼 문장 토크나이징 함수를 불러온 후 데이터에 적용해 보자.
from nltk.tokenize import sent_tokenize
sentence = 'Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. The result is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.'
print(sent_tokenize(sentence))['Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data.', 'The result is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them.', 'The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.']사용법은 단어를 기준으로 나눴을 때와 크게 다르지 않다. 그냥 데이터를 sent_tokenize 함수에 적용하기만 하면 자동으로 문장 기준으로 나눠준다. 결과를 보면 위의 텍스트가 문장으로 나눠진 리스트로 나오는 것을 알 수 있다. 이처럼 라이브러리를 사용하면 원하는 기준으로 간단하게 토크나이징할 수 있다.
그뿐만 아니라 NLTK 라이브러리의 경우 토크나이징 외에도 자연어 처리에 유용한 기능들을 제공한다. 대표적으로 텍스트 데이터를 전처리할 때 경우에 따라 불용어를 제거해야 할 때가 있다. 여기서 불용어란 큰 의미를 가지지 않는 단어를 의미한다. 예를 들어, 영어에서는 'a', 'the' 같은 관사나 'is'와 같이 자주 출현하는 단어들을 불용어라 한다. NLTK 라이브러리에는 불용어 사전이 내장되어 있어서 불용어를 정의 할 필요 없이 바로 사용할 수 있다.
2) Spacy
Spacy는 NLTK와 같은 오픈소스 라이브러리이다. 주로 연구, 교육 목적이 아닌 상업 목적으로 만들어졌다는 점에서 NLTK와 다른 목적으로 만들어진 라이브러리이다. Spacy는 현재 영어를 포함한 8개 국어에 대한 자연어 전처리 모듈을 제공하고 빠른 속도로 전처리할 수 있다. 또한 쉽게 설치하고 원하는 언어에 대한 전처리를 한 번에 해결할 수 있다는 장점이 있으며, 특히 딥러닝 언어 모데의 개발도 지원하고 있어서 매력적이다.
Spacy 토크나이징
NLTK 라이브러리에서는 단어 단위의 토크나이징 함수는 word-tokenize(), 문장 단위의 토크나이징 함수는 sent_tokenize()로 서로 구분돼 있었다. 하지만 Spacy에서는 두 경우 모두 동일한 모듈을 통해 토크나이징 한다.
먼저 spacy.load('en')을 통해 토크나이징할 객체를 생성해서 nlp 변수에 할당한다. 그리고 토크나이징할 텍스트를 sentence에 할당해서 nlp(sentence)를 실행해 nlp객체에 대해 호출하면 된다. 그러고 나면 텍스트에 대해 구문 분석 객체를 반환하는데 이를 doc 변수에 할당한다. 이제 doc 객체를 가지고 입력한 텍스트에 대한 단어 토크나이징과 문장 토크나이징을 할 수 있다.
import spacy
nlp = spacy.load('en')
sentence = 'Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. The result is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.'
doc = nlp(sentence)
word_tokenized_sentence = [token.text for token in doc]
sentence_tokenized_list = [sent.text for sent in doc.sents]
print(word_tokenized_sentence)
print(sentence_tokenized_list)['Natural', 'language', 'processing', '(', 'NLP', ')', 'is', 'a', 'subfield', 'of', 'linguistics', ',', 'computer', 'science', ',', 'and', 'artificial', 'intelligence', 'concerned', 'with', 'the', 'interactions', 'between', 'computers', 'and', 'human', 'language', ',', 'in', 'particular', 'how', 'to', 'program', 'computers', 'to', 'process', 'and', 'analyze', 'large', 'amounts', 'of', 'natural', 'language', 'data', '.', 'The', 'result', 'is', 'a', 'computer', 'capable', 'of', '"', 'understanding', '"', 'the', 'contents', 'of', 'documents', ',', 'including', 'the', 'contextual', 'nuances', 'of', 'the', 'language', 'within', 'them', '.', 'The', 'technology', 'can', 'then', 'accurately', 'extract', 'information', 'and', 'insights', 'contained', 'in', 'the', 'documents', 'as', 'well', 'as', 'categorize', 'and', 'organize', 'the', 'documents', 'themselves', '.']
['Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data.', 'The result is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them.', 'The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.']
NLTK는 함수를 통래 토크나이징을 처리했지만, Spacy는 객체를 생성하는 방식으로 구현돼있다. 이처럼 객체를 생성하는 이유는 이 객체를 통해 단순히 토크나이징뿐 아니라 갖가지 다른 자연어 전처리 기능을 제공할 수 있기 때문이다.
2. 한글 토크나이징 라이브러리
자연어 처리에서 각 언어마다 모두 특징이 다르기 때문에 천편일률적으로 동일한 방법을 적용하기는 어렵다. 한글에도 NLTK나 Spacy 같은 도구를 사용할 수 있으면 좋겠지만 언어 특성상 영어를 위한 도구를 사용하기에는 적합하지 않다. 하지만 다행히도 영어 자연어 처리를 위한 도구와 같이 한들 자연어 처리를 돕는 도구가 있다. 여러 가지 도구가 있지만 여기서는 한글 자연어 처리에 많이 사용하는 파이썬 라이브러리인 KoNLPy에 대해 알아보겠다. KoNLPy는 형태소 분석으로 형태소 단위의 토크나이징을 가능하게 할뿐만 아니라 구문 분석을 가능하게 해서 언어 분석을 하는데 유용한 도구이다.
1) KoNLPy
KoNLPy는 한들 자연어 처리를 쉽고 간결하게 처리할 수 있도록 만들어진 오픈소스 라이브러리다. 또한 국내에 이미 만들어져 사용되고 있는 형태소 분석기를 사용할 수 있게 허용한다. 일반적인 어절 단위에 대한 토크나이징은 NLTK로 충분히 해결할 수 있으므로 여기서는 형태소 단위에 대한 토크나이징에 대해 알아보겠다.
형태소 단위 토크나이징
한글 텍스트의 경우에는 형태소 단위 토크나이징이 필요할 때가 있다. KoNLPy에서는 여러 형태소 분석기를 제공하며, 각 형태소 분석기별로 분속한 결과는 다를 수 있다. 각 형태소 분석기는 클래스 형태로 되어 있고 이를 객체로 생성한 후 메서드를 호출해서 토크나이징 할 수 있다.
형태소 분석 및 품사 태깅
형태소란 의미를 가지는 가장 작은 단위로서 더 쪼개지면 의미를 상실하는 것들을 말한다. 따라서 형태소 분석이란 의미를 가지는 단위를 기준으로 문장을 살펴보는 것을 의미한다.
KoNLPy 이전에 C, C++, Java 언어를 통해 형태소 분석을 할 수 있는 좋은 라이브러리들이 있었다. KoNLPy는 이러한 기존의 형태소 분석기들을 파이썬 라이브러리로 통합해서 사용할 수 있게 했고, 그 결과 한국어 구문 분석을 쉽게 할 수 있게 됐다. KoNLPy에는 다양한 형태소 분석기들이 객체 형태로 포함돼 있으며 각 형태소 분석기의 목록은 다음과 같다.
- Hannanum
- Kkma
- Komoran
- Mecab (Windows OS에서 사용 할 수 없다.)
- Okt(Twitter)
위 객체들은 모두 동일하게 형태소 분석 기능을 제공하는데, 각기 성능이 조금씩 다르므로 직접 비교해보고 자신의 데이터를 가장 잘 분석하는 분석기를 사용하길 권장한다. 본 포스팅에선 Okt의 사용법을 설명한다. Okt는 원래 이름이 Twitter였으나 0.5.0 이후 버전부터 이름이 Okt로 바뀌었다.
Okt 객체는 다음과 같은 4개의 함수를 제공한다.
1. okt.morphs( )
텍스트를 형태소 단위로 나눈다. 옵션으로는 norm과 stem이 있다. 각 True or False 값을 받으며, norm은 nomalize의 약자로서 문장을 정규화하는 역할을 하고, stem은 각 단어의 어간을 추출하는 기능이다. 각각 True로 설정하면 각 기능이 적용된다. 옵션을 지정하지 않으면 기본값은 둘 다 False로 설정된다.
2. okt.nouns( )
텍스트에서 명사만 뽑아낸다.
3 okt.phrases( )
텍스트에서 어절을 뽑아낸다.
4.okt.pos( )
위의 세 함수는 어간/명사/어절 등을 추출해내는 추출기로 동작했다면 pos 함수는 각 품사를 태킹하는 역할을 한다. 품사를 태깅한다는 것은 주어진 텍스트를 형태소 단위로 나누고 나눠진 각 형태소를 그에 해당하는 품사와 함께 리스트화하는 것을 의미한다. 이 함수에서도 옵션을 설정할 수 있는데, morphs 함수와 마찬가지로 norm, stem 옵션이 있고 추가적으로 join 함수가 있는데 이 옵션 값을 True로 설정하면 나눠진 형태소와 품사를 형태소/품사 형태로 같이 분여서 리스트화 한다.
from konlpy.tag import Okt
okt=Okt()text='한글 자연어 처리는 재밌다 이제부터 열심히 해야지 ㅎㅎㅎ'
print(okt.morphs(text))
print(okt.morphs(text,stem=True))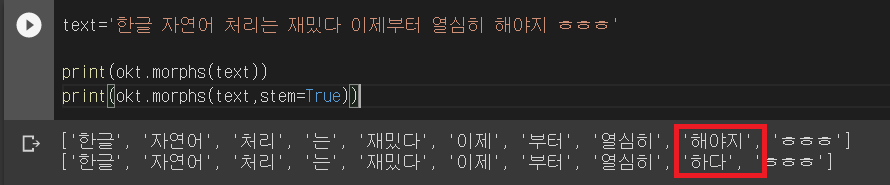
stem(어간) 옵션을 주지 않은 경우 '해야지', 준 경우 '하다'가 추출된 것을 볼 수 있다.
print(okt.nouns(text)) #명사단위
print(okt.phrases(text)) #어절단위
print(okt.pos(text))
print(okt.pos(text,join=True)) #형태소와 품사를 붙여서 리스트화
'인공지능, 자연어처리 > 텐서플로2와 머신러닝으로 시작하는 자연어처리' 카테고리의 다른 글
| 3장 자연어 처리 개요(2) : 텍스트 분류 (0) | 2021.01.05 |
|---|---|
| 3장 자연어 처리 개요(1) : 단어표현 (0) | 2021.01.05 |
| 2장 자연어 처리 개발 준비(4) : 그 밖의 라이브러리 (0) | 2021.01.03 |
| 2장 자연어 처리 개발 준비(2) : 사이킷런 (0) | 2020.12.30 |
| 2장 자연어처리 개발 준비(1) : 텐서플로 (2) | 2020.12.26 |
- Total
- Today
- Yesterday
- 코딩테스트
- 인공지능
- NLP
- text classification
- 젠심
- django
- Tutorial
- Polls
- CBOW
- 로버트존슨
- 자연어처리
- 융
- word2vec
- 알고스팟
- word embedding
- 분석심리학
- 당신의 그림자가 울고 있다.
- 텍스트분류
- web
- Skip-gram
- 심리학
- Mikolov
- Python
- 단어표현
- 그림자
- WebProgramming
- 코딩하는 신학생
- AI
- lstm
- word vector
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |