
티스토리 뷰
[논문리뷰]Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
CoShin 2021. 3. 14. 22:26Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling

Abstract
본 논문에서는 다양한 타입의 RNN을 비교한다. 특히, LSTM과 GRU같이 gating machanism을 갖고 있는 RNN에 집중한다. polyphonic music modeling과 speech signal modeling을 해당 RNN을 이용하여 평가하였다. 실험결과 advanced RNN은 전통적인 RNN보다 나은 성능을 보였으며 또한, GRU는 LSTM과 견줄만한 성능을 보였다.
1. Introduction
RNN은 input과 output에서 다양한 길이를 가지고 있는 machine learning task에서 좋은 성능을 보였다. 특히 최근에는 기계번역 분야에서 좋은 성능을 보이고 있다. 한 가지 흥미로운 점은, 최근 훌륭한 성과를 보인 모델들은 vanilla RNN이 아니라 LSTM과 같은 hidden recurrent unit을 갖은 모델이었다는 것이다.
본 논문에서는 이러한 철학을 가지고 있는 두 모델 LSTM, GRU 그리고 전통적인 tanh 유닛을 평가하였다. 모델을 평가하기 위하여 polyphonic music dataset을 이용하였다.
2. Background : Recurrent Neural Network
RNN은 다양한 길이의 연속적인 input을 다룰수 있는 전통적인 Neural Network이다. RNN은 매 실행마다 동작하는 recurrent hidden state를 이용하여 이전 input에 의존적인 연속적인 input을 handling한다.
더욱 명료하게 표현하면 주어진 sequence X = {x1, x2, x3 ... xr}에 대하여, RNN의 hidden state ht는 다음과 같이 정의된다.

이때, φ는 로지스틱 simoid와 같은 비선형함수이다. 최적으로, RNN은 Y = {y1, y2, y3, ... yr}과 같이 다양한 길이를 가질 수 있는 output을 가지고 있다.
전통적으로, recurrent hidden state는 다음과 같이 실행된다.

이때 g는 sigmoid와 hyperbolic tangent와 같은 smooth, bounded function이다.
RNN은 주어진 현재 state ht에 대하여 sequence의 다음 element에 대한 확률 분포를 생성해낸다. 그리고 generative model은 다양한 길이의 분포를 포착할 수 있다. Sequence probability는 다음과 같이 분해될 수 있다.
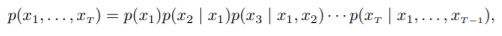
이때 마지막 element는 sequence value의 특별한 마지막 값이다. 이 모델은 다음과 같은 조건부확률로 표현 될 수 있다.

이때 g와 ht는 위 수식에서 표현된 값이다.
불행히도, 긴 input에 대하여 훈련하기 어려운 한계를 가지고 있다. 왜냐하면 gradient가 매우 작아지거나(vanish), 매우 커지는(explode) 문제가 생기기 때문이다. 이러한 문제는 gradient를 기반으로 최적화 하는 방법을 어렵게 만든다. 이러한 이슈를 해결하기 위해 이전에 소개되었던 대표적인 두 방법이 있다. 한 가지 접근법은 아주 간단하게 clipped gradient를 이용하여 해결하는 것이다.
또다른 접근 방법은 gating unit을 이용하여 해결하는 것이다. 가장 쉽게 시도 되었던 적접적으로 activation을 이용하거나 LSTM이라고 불리는 recurrent unit을 이용하는 것이다. 더욱 최근 소개 되었던 또 다른 recurrent unit인 GRU도 있다. 이러한 unit들은 음성인식과 기계번역에서 좋은 결과를 보였다.

3. Gated Recurrent Neural Networks
본 논문에서는 sequence modeling에서 LSTM과 GRU를 비교한다. 실험적인 평가 이전에 각 recurrent unit을 묘사하여보자.
3.1 Long Short-Term Memory Unit
최초의 LSTM은 Hochreiter and Schidhuber에 의하여 제안되었고, original LSTM을 약간 수정하여 만든 많은 LSTM이 존재한다. 본 논문에서는 Graves의 LSTM을 소개한다.
단순하게 input의 가중합과 비선형적 speech signal modeling을 해당 RNN을 이용하여 평가하였다. 실험결과 advanced RNN은 전통적인 RNN보다 나은 성능을 보였으며 또한, GRU는 LSTM과 견줄만한 성능을 보였다.
단순하게 input의 가중합으로 계산되는 recurrent unit과는 다르게 각 jth LSTM unit은 각 시간 t에 대한 memory C(j,t)의 값을 유지한다. h(j,t)의 output은 다음과 같은 수식에 의해 계산된다.

이때 o(j,t)는 output gate인 memory content exposure의 총 합이다. 이러한 output gate는 다음과 같은 수식에 의하여 계산된다.
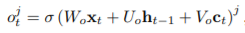
위 수식에서 σ는 logistic sigmoid 함수이고 Vo는 diagonal martix이다.
메모리 셀 c(j, t)는 존재했던 메모리 일부를 잊고 새로운 memory content c(~j, t)를 추가함으로 갱신된다.

이때 새로운 memory content는 다음과 같이 계산된다.

존재하는 메모리를 잊는 범위는 forget gate f(j, t)에 의하여 계산된다. 그리고 새로운 content가 더해지는 정도는 input gate i(j, t)에 의하여 계산된다.

Vf는 Vi의 diagonal matrices이다.
매 step마다 unit의 값을 overwrite하는 전통적인 RNN과는 다르게, LSTM unit은 기존의 정보를 유지할지 아닐지를 앞서 소개된 gate에 의하여 결정한다. 직관적으로 LSTM unit이 이전에 입력받은 sequence로부터 중요한 frature를 찾아낸다면, 이것은 더 길게 정보를 유지할 수 있고, 긴 거리에 대하여 잠재적인 capturing이 가능한 것이다.
3.2 Gated Recurrent Unit
A geted recurrent unit(GRU)는 조경현 박사님에 의하여 각 recurrent unit에 의하여 서로 다른 time scale을 가지고 있는 의존성을 파악하기 위해 제안된 모델이다. LSTM과 유사하게 GRU는 unit안에서 메모리가 계산되고 분리된 memory cell이 없다는 특징을 가지고 있다.
GRU의 activation h(j, t)은 이전의 h(j, t-1)과 앞으로 나오게 될 h(~j,t) 사이에 대한 선형 보강법(linear interpolation)이다.

이때 update gate z(j, t)는 그것의 content가 업데이트 된 정도값이다. update gate z(j, t)는 다음과 같이 계산된다.

존재하는 state와 새로운 state 사이에서의 선형적인 합을 얻기위한 이 과정은 LSTM unit과 유사하다. 하지만 GRU는 상태가 노출되는 정도를 조절 할 수 있는 메커니즘을 가지고 있지 않고 매번 모든 전체 상태를 노ㅜㄹ시킨다.
앞으로 들어올 candidate activation h(~j, t)는 전통적인 recurrent unit과 유사하게 다음과 같은 수식으로 계산된다.

이때 r_t는 reset gate이고,r_t와ht-1는 element-wise multiplication으로 계산된다. 이때, r_t가 0에 가까워 질 때, reset gate는 마치 이전에 계산되었던 모든 unit의 값을 잊고 첫 unit을 input으로 받아들이는 것과 같이 unit ate를 효율적으로 만들 수 있다. Reset gate는 다음과 같은 수식에 의하여 계산될 수 있다.

3.3 Discussion
LSTM과 GRU가 공유하고 있는 가장 두드러지는 요소는 t에서 t+1로 업데이트 되는 과정에서 component가 더해진다는 것이다. 전통적인 RNN 모델에서는 더해지는 것이 아니라 새로운 value로 대체되었다. LSTM과 GRU의 또 다른 공통점은 새로운 content가 memory의 top이라는 것이다.
이러한 부가적인 요소는 두 가지 장점을 가지고 있다. 첫 째, 긴 series step을 위하여 각 unit은 특별한 feature의 존재를 기억한다. 또 다른 중요한 점은 LSTM의 forget data와 GRU의 update gate는 전통적인 RNN의 overwrite를 대신하여 이전의 정보를 유지할 정도를 결정하는 것이다.
둘 째, 덧셈은 효율적으로 여러 step에 연결될 수 있는 shorcut path를 만든다. 이러한 shortcut은 오차 역전파에서 쉽게 vanishing gradient문제를 해결해준다.
하지만 이 두 unit은 다른 점을 가지고 있다. GRU에는 없는 LSTM의 특징은 memory content의 노출을 조절한다는 것이다. LSTM은 output gate에 의하여 memory content가 노출되는 정도를 조절하는 반면, GRU는 이러한 장치가 전혀 없다.
또 다른 점은 reset gate에 해당하는 input gate의 location이다. LSTM은 이전의 메모리의 총 양을 조절하는 것과 분리없이 새로운 memory content를 계산한다. 게다가, LSTM unit은 새로운 memory content의 총 양을 forget gate의 독립적인 cell과 더해져서 조절된다. 또 다른 점은 GRU는 이전의 연산에 의하여 정보의 흐름을 조절하지만, 독립적으로 정보의 총 양을 조절하지는 않는다.
4. Experiments Setting
4.1 Tasks and Datasets
Sequence modeling task에서 LSTM, GRU 그리고 tanh를 비교한다. Sequence modeling은 log-likelibood를 최대화하여 sequence를 넘어선 확률 분포를 학습하는 것을 목적으로 한다.

이때, setha는 model parameter의 집합이다. 더 구체적으로 본 논문에서는 polyphonic music modeling 과 speech signal modeling에 대하여 평가한다.
Polyphonic music data setdms ts from [BoulangerLewandowski et al., 2012]: Nottingham, JSB Chorales, MuseData and Piano-midi를 이용한다. 또한 speech signal dataset은 Unisoft에서 제공하는 dataset을 이용한다.
4.2 Model
각 tasl를 서로 다른 세 가지 RNN인 tanh-RNN, LSTM, GRU에 대하여 평가한다. 이 실험의 가장 중요한 목적은 세 unit을 공평하게 비교하는 것이다. 따라서 본 논문의 실험에서는 세 모델을 근사하게 같은 수의 파라메터 갖게 설정하였다. overfitting을 피하기 위하여 파라메터를 적게 사용하였다. 다음 테이블은 모델의 크기와 실험 결과를 보여준다.

각 모델을 RMSProp optimizer을 이용하여 훈련시켰고, weight noise는 standard deviation 0.075로 고정하였다. 각 update마다 gradient exploding을 방지하기 위하여 gradient의 norm의 크기가 1을 넘어간다면 gradient의 norm을 1로 축소시켰다.
5. Results and Analysis
Table2는 실험 결과를 보여주고 있다. polynomic music dataset의 경우 GRU는 LSTM과 tanh-RNN보다 더 나은 결과를 보였지만 music dataset에서는 세 모델의 성능차이가 크지 않았다.
또다른 경우, 음성인식 task의 경우 LSTM과 GRU가 전통적인 tanh-RNN보다 더 나은 성능을 보였다.


'인공지능, 자연어처리' 카테고리의 다른 글
- Total
- Today
- Yesterday
- Tutorial
- 단어표현
- 그림자
- Skip-gram
- django
- 심리학
- WebProgramming
- CBOW
- 융
- 자연어처리
- 젠심
- 분석심리학
- word embedding
- 당신의 그림자가 울고 있다.
- Polls
- 인공지능
- text classification
- lstm
- 텍스트분류
- AI
- NLP
- 로버트존슨
- word vector
- Mikolov
- web
- word2vec
- 알고스팟
- 코딩하는 신학생
- 코딩테스트
- Python
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |